아래와 같은 쿼리와 트레이스 결과가 있습니다.
-- 인덱스 구성
-- IX00_LOG :LOGIN_DT , ITS
-- PK_EMP : EMP_NO
SELECT L.SEQ , L.WB_TYPE, L.ITS , E.E_NAME, E.DEPE_NO, E.EMP_CODE
FROM TB_LOG L , TB_EMP E
WHERE 1 = 1
AND L.EMP_NO = E.EMP_NO
AND L.LOGIN_DT BETWEEN '20220101' AND '20220131'
AND L.ITS = 'CMEA' ;
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 2268 |00:00:00.14 | 7228 |
| 1 | NESTED LOOPS | | 1 | | 2268 |00:00:00.14 | 7228 |
| 2 | NESTED LOOPS | | 1 | 2164 | 2268 |00:00:00.14 | 4960 |
| 3 | TABLE ACCESS BY INDEX ROWID| TB_LOG | 1 | 2164 | 2268 |00:00:00.14 | 4929 |
|* 4 | INDEX RANGE SCAN | IX00_LOG | 1 | 2164 | 2268 |00:00:00.14 | 4826 |
|* 5 | INDEX UNIQUE SCAN | PK_EMP | 2268 | 1 | 2268 |00:00:00.01 | 31 |
| 6 | TABLE ACCESS BY INDEX ROWID | TB_EMP | 2268 | 1 | 2268 |00:00:00.01 | 2268 |
---------------------------------------------------------------------------------------------------------트레이스를 확인하여 보면, IX00_LOG 인덱스를 Range Scan하는 과정에서 4826개의 블록을 읽어서 2268개의 레코드를 찾았습니다. 테이블에 갔을 때에는 모든 레코드가 다 살아납았습니다.
테이블 액세스는 많지 않지만 인덱스 Range Scan과정에서 비효율이 있는것으로 보입니다.
우선 여기까지만 봤을 때, 인덱스에 추가되어있는 컬럼들은 문제가 없다는 것을 알수 있습니다.
일반적으로 이럴 경우에 인덱스 내의 컬럼 순서를 조정하면 개선이 될 수 있습니다.
여기까지 확인하고 쿼리를 살펴보겠습니다.
TB_LOG 테이블의 2022년 1월달 중 ITS 값이 'CMEA' 인것을 찾는 쿼리입니다.
건수를 조회해보니 한달 건수는 1,546,774입니다.
즉, 2268건을 찾기위해 한달 데이터 1,546,774건을 인덱스 스캔하고 있습니다.
인덱스 선두컬럼인 LOGIN_DT를 BETWEEN으로 조회하여 ITS가 필터처리되어 발생하는 비효율이 있습니다.
예상대로 위 컬럼의 인덱스 순서를 조정하면 해결이 될것으로 보입니다.
하지만, 인덱스를 신규 추가하기가 부담스러운 상황이라면 다른 방법은 없을까요?
인덱스 선두컬럼인 LOGIN_DT는 YMD로 입력되는 컬럼으로, 한달 조회 시 Cardinaliry는 30입니다. 한달 전체건수인 1,546,774에 비해 적은것으로 보이네요. 이럴때 큰 효과를 발휘하는게 INDEX SKIP SCAN입니다.
인덱스 SKIP SCAN은 인덱스 리프블록을 탐색 할 때 필요없는 값을 뛰어넘어서(SKIP)해서 읽는 방식인데요, 이게 가능한 이유는 인덱스는 정렬이 보장되어 있기 때문입니다. 정렬이 보장되어 있기 때문에, 인덱스 내에서 필터 방식으로 처리를 하여도 읽지 않아도 될 데이터를 알수 있습니다.
AND L.LOGIN_DT BETWEEN '20220101' AND '20220131'
AND L.ITS = 'CMEA'
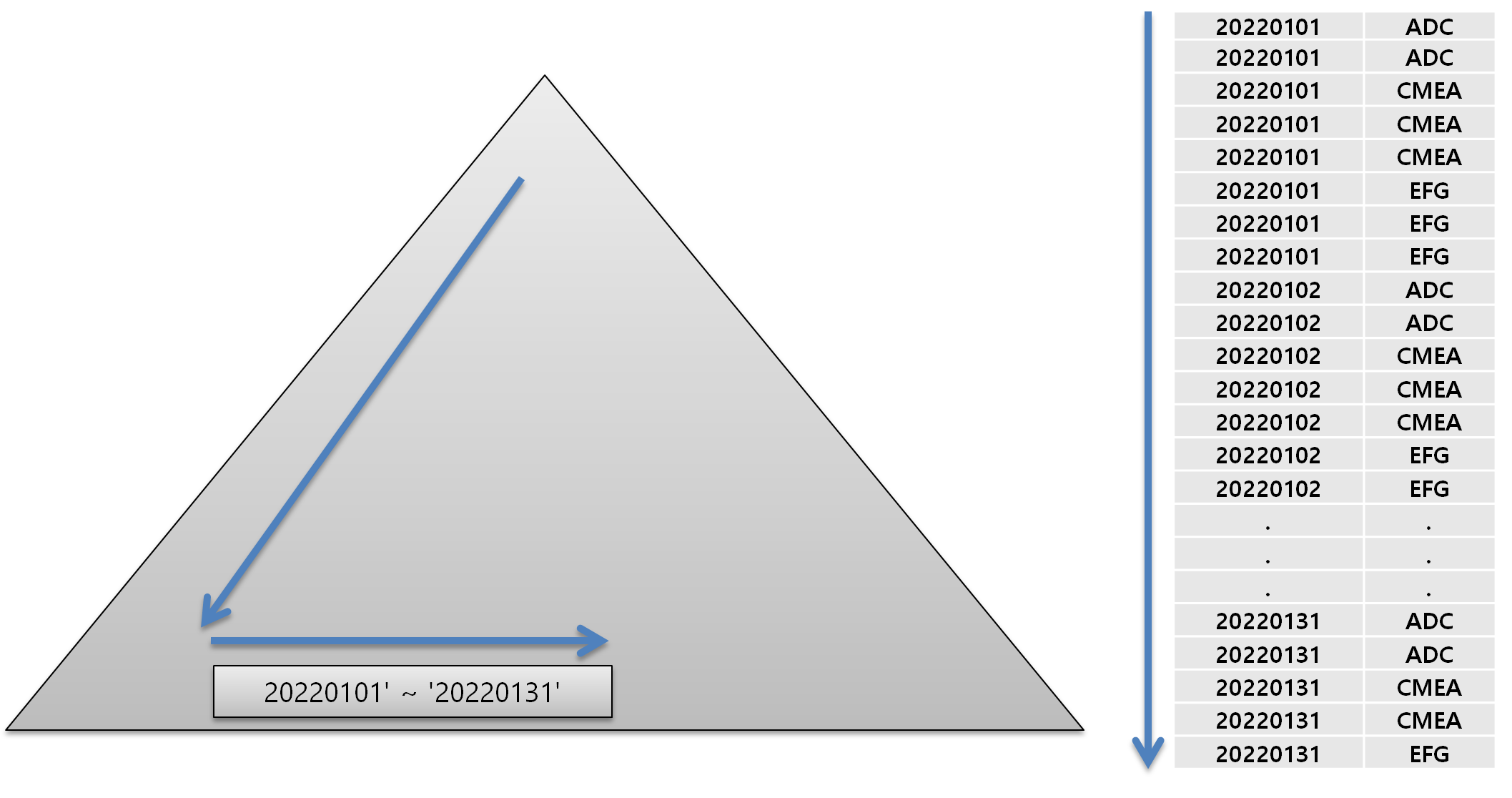
LOGIN_DT + ITS로 순서로 인덱스가 생성되어 있으니 Range Scan은 위 그림과 같이 진행됩니다. 액세스조건 들어오는 모든 범위의 값들을 스캔하며 액세스조건이 아닌 값들을 필터링 하게 됩니다.
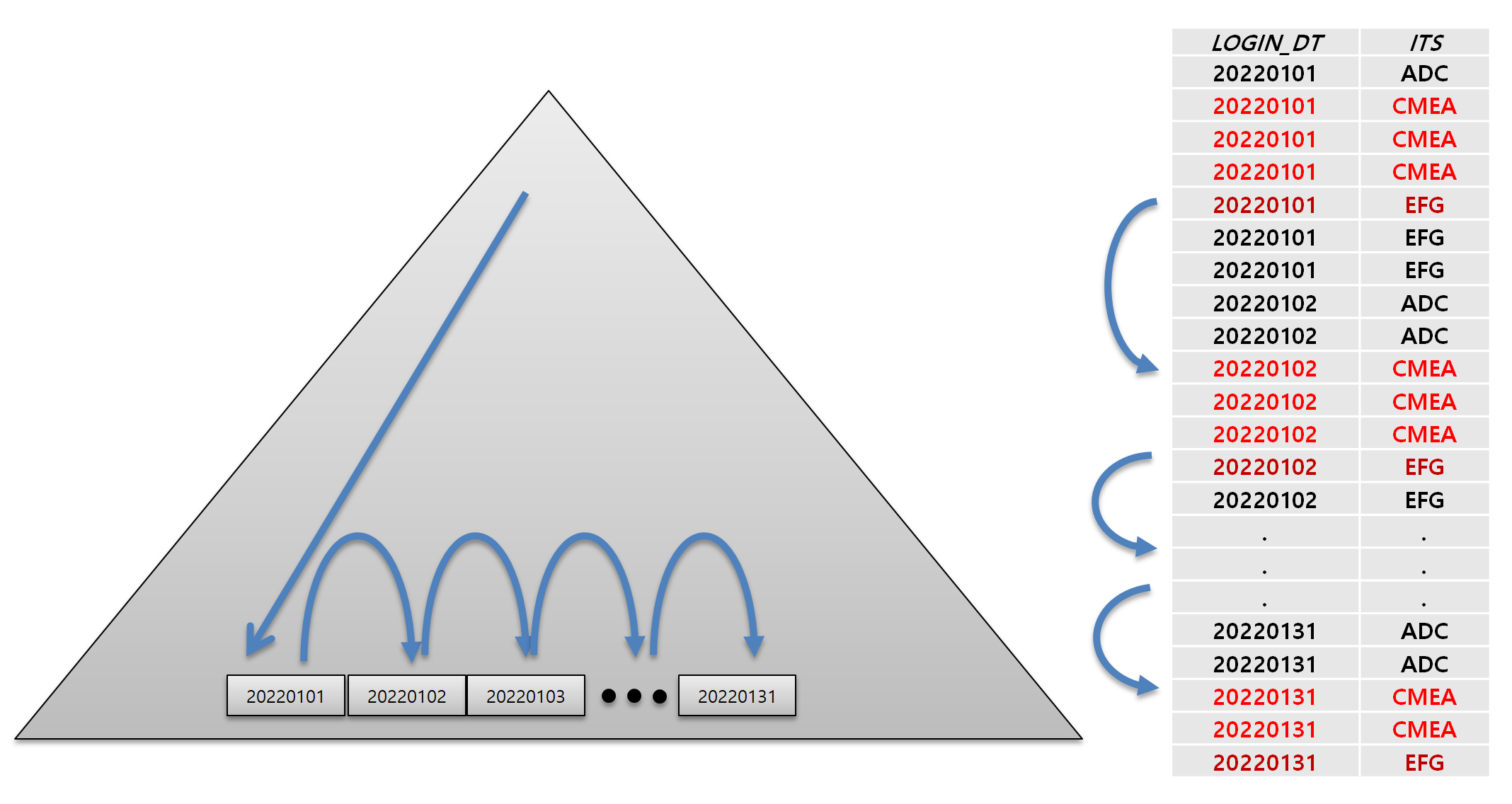
하지만 인덱스는 값이 정렬되어 있기 때문에 찾아야 할 데이터보다 큰 값이 나오게 되면, 더이상 그 뒤에 값을 탐색하는건 의미가 없습니다. ORACLE은 이 방식으로 값을 찾아나가며, 더이상 스캔이 필요없는 데이터는 SKIP하게 됩니다.
LOGIN_DT + ITS 순으로 정렬되어 저장되어있는 인덱스를 탐색하는 중, ITS값이 찾아야 할 값보다 더 큰 값이 나올 경우 다음 LOGIN_DT의 블록으로 SKIP을 하게 되는거죠.
인덱스 SKIP SCAN HINT를 적용해서 쿼리를 수행해 보았습니다.
SELECT /*+ index_ss(o IX00_LOG) */
L.SEQ , L.WB_TYPE, L.ITS , E.E_NAME, E.DEPE_NO, E.EMP_CODE
FROM TB_LOG L , TB_EMP E
WHERE 1 = 1
AND L.EMP_NO = E.EMP_NO
AND L.LOGIN_DT BETWEEN '20220101' AND '20220131'
AND L.ITS = 'CMEA' ;
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 2268 |00:00:00.01 | 2567 |
| 1 | NESTED LOOPS | | 1 | | 2268 |00:00:00.01 | 2567 |
| 2 | NESTED LOOPS | | 1 | 2164 | 2268 |00:00:00.01 | 299 |
| 3 | TABLE ACCESS BY INDEX ROWID| TB_LOG | 1 | 2164 | 2268 |00:00:00.01 | 268 |
|* 4 | INDEX SKIP SCAN | IX00_LOG | 1 | 2164 | 2268 |00:00:00.01 | 165 |
|* 5 | INDEX UNIQUE SCAN | PK_EMP | 2268 | 1 | 2268 |00:00:00.01 | 31 |
| 6 | TABLE ACCESS BY INDEX ROWID | TB_EMP | 2268 | 1 | 2268 |00:00:00.01 | 2268 |
---------------------------------------------------------------------------------------------------------
신규 인덱스를 추가 했을때와 얼마나 차이나는지 비교해보겠습니다.
-- 인덱스 추가
-- IX01_LOG : ITS , LOGIN_DT
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 2268 |00:00:00.01 | 2436 |
| 1 | NESTED LOOPS | | 1 | | 2268 |00:00:00.01 | 2436 |
| 2 | NESTED LOOPS | | 1 | 2164 | 2268 |00:00:00.01 | 168 |
| 3 | TABLE ACCESS BY INDEX ROWID| TB_LOG | 1 | 2164 | 2268 |00:00:00.01 | 137 |
|* 4 | INDEX RANGE SCAN | IX01_LOG | 1 | 2164 | 2268 |00:00:00.01 | 34 |
|* 5 | INDEX UNIQUE SCAN | PK_EMP | 2268 | 1 | 2268 |00:00:00.01 | 31 |
| 6 | TABLE ACCESS BY INDEX ROWID | TB_EMP | 2268 | 1 | 2268 |00:00:00.01 | 2268 |
---------------------------------------------------------------------------------------------------------
인덱스 생성없이 기존의 인덱스를 SKIP SCAN하는 방식보다 131블록밖에 차이가 나지 않습니다.
DML부하 및 인덱스 관리비용 등을 생각해보면 신규 인덱스 추가보다 기존의 인덱스를 SKIP SCAN하는것이 유리할것으로 보입니다.
INDEX SKIP SCAN의 핵심은 위와 같이 선두컬럼의 중복값이 많아 SKIP하는 데이터가 많을 때 의미가 있습니다.
위와 같이 일자컬럼을 SKIP할 때에는 한달의 데이터가 아무리 많아도, 최종적으로 30번만 Skip하면 되지만, 시분초까지 저장되는 일시별 컬럼을 SKIP하는 것은 의미가 없습니다.
'DB' 카테고리의 다른 글
| OracleDB Call최소화 : ArraySize조절을 통한 Fetch Call 최소화 (0) | 2022.06.26 |
|---|---|
| OracleDB IOT로 MariaDB/MySQL 인덱스 이해하기 (0) | 2022.06.19 |

