1. Call통계

① Parse Call : SQL 처리 루틴 생성 (캐싱 되어 있으면 그것을 사용)
② Execute Call : SQL 실행 요청
③ Fetch Call : 데이터 전송 요청
④ Misses in library cashe during parse : 하드파싱 횟수
2. User Call과 Recursive Call
▶ User Call
- 네트워크를 통해 외부에서 들어오는 Call을 말하며, DBMS입장에서 User Call은 WAS와 API서버를 말함.
- 동시 접속자 수가 적을 때는 잘 느끼지 못하지만, PeakTime에 시스템 장애를 발생시키는 주범
- 집합적 사고를 통해 Loop-Query를 해소하고 One-SQL로 구현해서 해소해야 함
- Array Processing기능 활용
▶ Recursive Call
- SQL파싱과 최적화 과정에서 발생하는 Data Dictionary 조회
- Function, Procedure, Trigger내에서 수행되는 SQL
- 부분범위처리가 가능한 상황에서 제한적으로 사용하거나, 조인 또는 Scalar Subquery 형태로 변환해야 함
3. Database Call 최소화 방안 요약

4. 직접 눈으로 보자!! : 오라클 성능고도화 1권 p366참고하여 테스트 진행
▶ Array Processing 활용 테스트
→ 테스트 Source 테이블 생성
drop table emp purge ;
create table emp
as
select object_id empno, object_name ename, object_type job
, round(dbms_random.value(1000, 5000), -2) sal
, owner deptno, created hiredate
from all_objects , (select rownum rn from dual connect by level <= 15 )
where rownum <= 1000000 ;
→ Target 테이블 생성
drop table emp2 purge ;
create table emp2
as
select * from emp where 1 = 2 ;
→ 테스트 시작 : Arraysize 10으로 Insert 수행
DECLARE
l_fetch_size NUMBER DEFAULT 10; -- 10건씩 Array 처리
CURSOR c IS
SELECT empno, ename, job, sal, deptno, hiredate
FROM emp;
TYPE array_empno IS TABLE OF emp.empno%type;
TYPE array_ename IS TABLE OF emp.ename%type;
TYPE array_job IS TABLE OF emp.job%type;
TYPE array_sal IS TABLE OF emp.sal%type;
TYPE array_deptno IS TABLE OF emp.deptno%type;
TYPE array_hiredate IS TABLE OF emp.hiredate%type;
l_empno array_empno := array_empno ();
l_ename array_ename := array_ename ();
l_job array_job := array_job ();
l_sal array_sal := array_sal ();
l_deptno array_deptno := array_deptno ();
l_hiredate array_hiredate := array_hiredate();
PROCEDURE insert_t( p_empno IN array_empno
, p_ename IN array_ename
, p_job IN array_job
, p_sal IN array_sal
, p_deptno IN array_deptno
, p_hiredate IN array_hiredate ) IS
BEGIN
FORALL i IN p_empno.first..p_empno.last
INSERT INTO emp2
VALUES ( p_empno (i)
, p_ename (i)
, p_job (i)
, p_sal (i)
, p_deptno (i)
, p_hiredate(i) );
EXCEPTION
WHEN others THEN
DBMS_OUTPUT.PUT_LINE(SQLERRM);
RAISE;
END insert_t;
BEGIN
OPEN c;
LOOP
FETCH c BULK COLLECT
INTO l_empno, l_ename, l_job, l_sal, l_deptno, l_hiredate
LIMIT l_fetch_size;
insert_t( l_empno, l_ename, l_job, l_sal, l_deptno, l_hiredate );
EXIT WHEN c%NOTFOUND;
END LOOP;
CLOSE c;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
END;
/
→ Arraysize 10의 Trace결과
SELECT EMPNO, ENAME, JOB, SAL, DEPTNO, HIREDATE FROM EMP
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.000 0.003 0 61 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 10001 0.031 0.187 570 10737 0 100000
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 10003 0.031 0.190 570 10798 0 100000
INSERT INTO EMP2 VALUES ( :B1 , :B2 , :B3 , :B4 , :B5 , :B6 )
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.000 0.000 0 0 0 0
Execute 10000 5.016 4.952 0 1824 18585 100000
Fetch 0 0.000 0.000 0 0 0 0
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 10001 5.016 4.952 0 1824 18585 100000
→ Arraysize 100으로 Insert 수행
truncate table emp2 ;
DECLARE
l_fetch_size NUMBER DEFAULT 100; -- 100건씩 Array 처리
CURSOR c IS
SELECT empno, ename, job, sal, deptno, hiredate
FROM emp;
TYPE array_empno IS TABLE OF emp.empno%type;
TYPE array_ename IS TABLE OF emp.ename%type;
TYPE array_job IS TABLE OF emp.job%type;
TYPE array_sal IS TABLE OF emp.sal%type;
TYPE array_deptno IS TABLE OF emp.deptno%type;
TYPE array_hiredate IS TABLE OF emp.hiredate%type;
l_empno array_empno := array_empno ();
l_ename array_ename := array_ename ();
l_job array_job := array_job ();
l_sal array_sal := array_sal ();
l_deptno array_deptno := array_deptno ();
l_hiredate array_hiredate := array_hiredate();
PROCEDURE insert_t( p_empno IN array_empno
, p_ename IN array_ename
, p_job IN array_job
, p_sal IN array_sal
, p_deptno IN array_deptno
, p_hiredate IN array_hiredate ) IS
BEGIN
FORALL i IN p_empno.first..p_empno.last
INSERT INTO emp2
VALUES ( p_empno (i)
, p_ename (i)
, p_job (i)
, p_sal (i)
, p_deptno (i)
, p_hiredate(i) );
EXCEPTION
WHEN others THEN
DBMS_OUTPUT.PUT_LINE(SQLERRM);
RAISE;
END insert_t;
BEGIN
OPEN c;
LOOP
FETCH c BULK COLLECT
INTO l_empno, l_ename, l_job, l_sal, l_deptno, l_hiredate
LIMIT l_fetch_size;
insert_t( l_empno, l_ename, l_job, l_sal, l_deptno, l_hiredate );
EXIT WHEN c%NOTFOUND;
END LOOP;
CLOSE c;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
END;
/
→ Arraysize 100의 Trace결과
SELECT EMPNO, ENAME, JOB, SAL, DEPTNO, HIREDATE FROM EMP
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 1001 0.047 0.061 0 1806 0 100000
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 1003 0.047 0.061 0 1806 0 100000
INSERT INTO EMP2 VALUES ( :B1 , :B2 , :B3 , :B4 , :B5 , :B6 )
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.000 0.000 0 0 0 0
Execute 1000 0.547 0.595 2 1791 8553 100000
Fetch 0 0.000 0.000 0 0 0 0
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 1001 0.547 0.595 2 1791 8553 100000
→ 위 Trace결과의 비교 분석
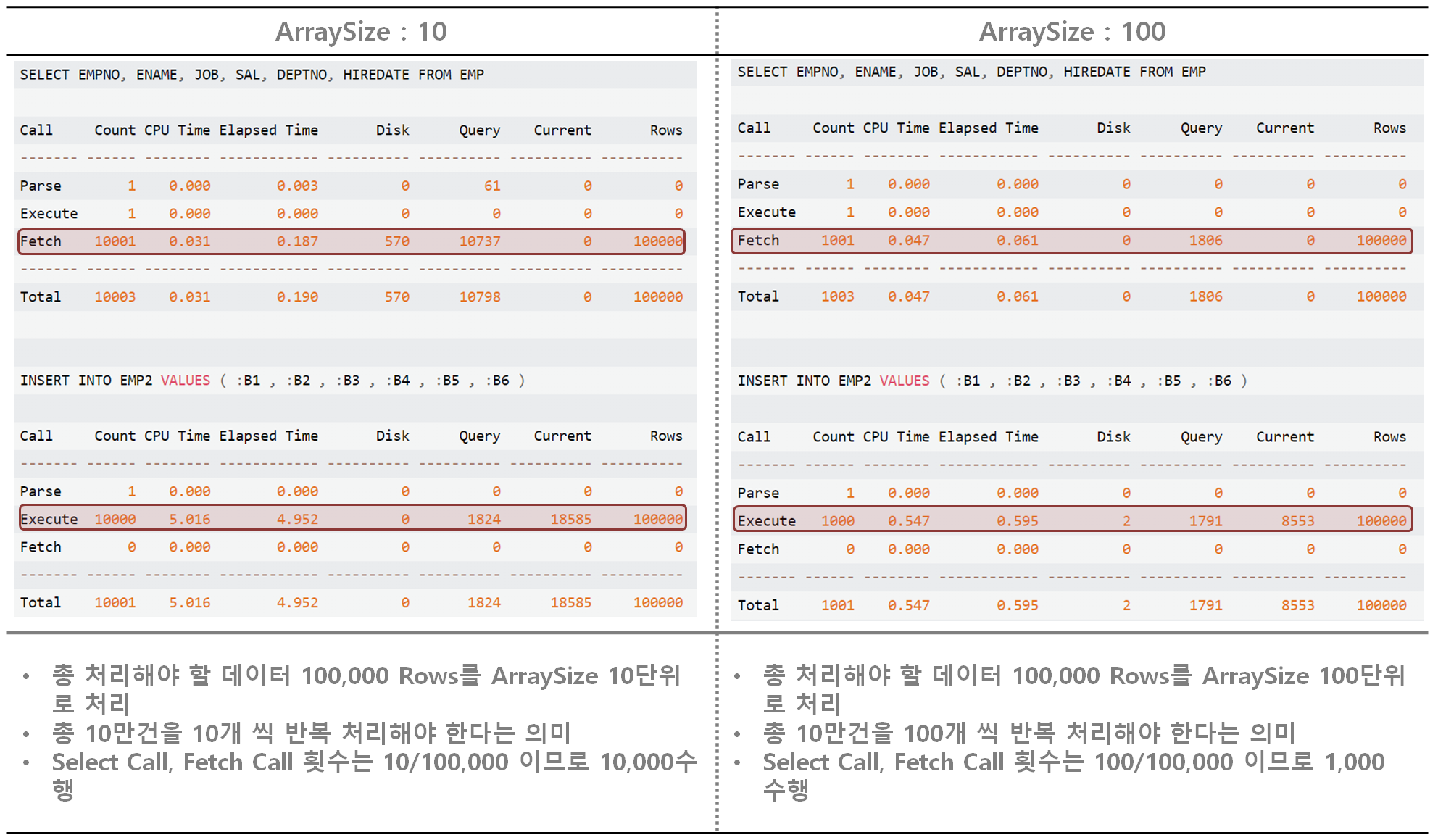
- Array Processing 활용으로 Fetch Call이 감소 되었음
- Array Processing의 효과를 극대화 하려면 연속된 일련의 처리과정이 모두 Array 단위로 진행되어야 함
- 예를들면, 최적의 Array단위로 앞서 Fetch를 하더라도, Insert단계에서 건건히 처리된다면 그 효과는 크게 반감됨
- 그렇다면 Array단위는 항상 크게 하는것이 좋을까?
→ ArraySize별 Fetch / IO갯수 확인
set autotrace traceonly statistics;
set timing on
set arraysize 2
select * from emp ;
set arraysize 5
select * from emp ;
set arraysize 10
select * from emp ;
set arraysize 15
select * from emp ;
set arraysize 100
select * from emp ;
set arraysize 5000
select * from emp ;
→ ArraySize 별 Fetch Count와 Block IO갯수 변화량
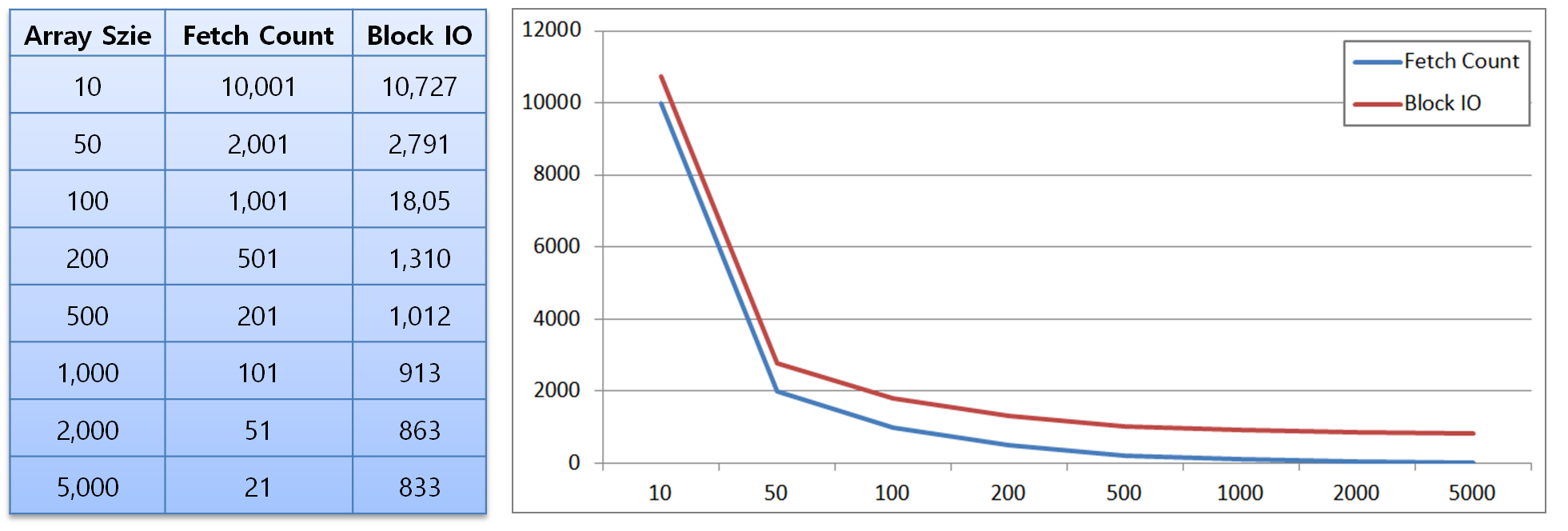
- 대량의 데이터를 Fetch할 때 ArraySize를 크게 설정하면 Fetch Call과 Block IO도 감소
- Fetch사이즈가 작으면 한번의 Fetch 완료 후 다시 데이터를 읽을 때 이 전에 읽었던 블록에 아직 읽어야 할 데이터가 있을 경우 동일 블록을 반복해서 읽기 때문
- ArraySize와 Block IO는 반비례하지만, 일정량이 넘어가면 더이상 감소하지 않음
- 일정수치가 넘어갈 경우 IO감소는 되지 않은 채 한번에 처리해야하는 양이 많아져 메모리부하 발생
'DB' 카테고리의 다른 글
| OracleDB IOT로 MariaDB/MySQL 인덱스 이해하기 (0) | 2022.06.19 |
|---|---|
| Oracle Index Skip Scan의 효용성 (0) | 2022.06.12 |

